K8s学习笔记
学习笔记
K8s
资源类型
k8s中的对象(资源类型)主要有4种,分为:
- 资源对象:Pod Deployment Statefulset Node Namespace等
- 存储对象:Volumn PersistentVolume等
- 策略对象
- 身份对象
每个对象会有两个字段来描述其信息,为Sepc和Status,前者为对象会被调度到的理想状态、后者为对象的当前状态,go-client中的Controller类就是专门做这件事的,他会通过ListWatch监听对象的当前状态,然后与其理想状态做对比,再进行对应的操作。
Raft
Raft协议为k8s的分布式存储提供了节点间状态同步的基础,核心算法为选举和日志复制
动画演示http://thesecretlivesofdata.com/raft/
Controller
Controller是k8s设计用来控制资源的类,可以从提供的官方示例来学习https://github.com/kubernetes/sample-controller.git,从零搭建一个自己的Controller网上也有不少案例,一个比较不错的:https://blog.csdn.net/boling_cavalry/article/details/88917818
sample-controller里定义了一个crd如下
1 | apiVersion: apiextensions.k8s.io/v1 |
这也是比较经典的CRD定义,tidb里的tidbCluster或者pd等其他资源类型都是如此定义,apply这个yaml就可以创建一个名为Foo,复数为foos的CRD
并且k8s也提供了一个实例模板
1 | apiVersion: samplecontroller.k8s.io/v1alpha1 |
这会创建一个名为example-foo的资源
然后我们自上而下看看controller是如何对foo资源进行控制的。
Sample-Controller解析
main.go
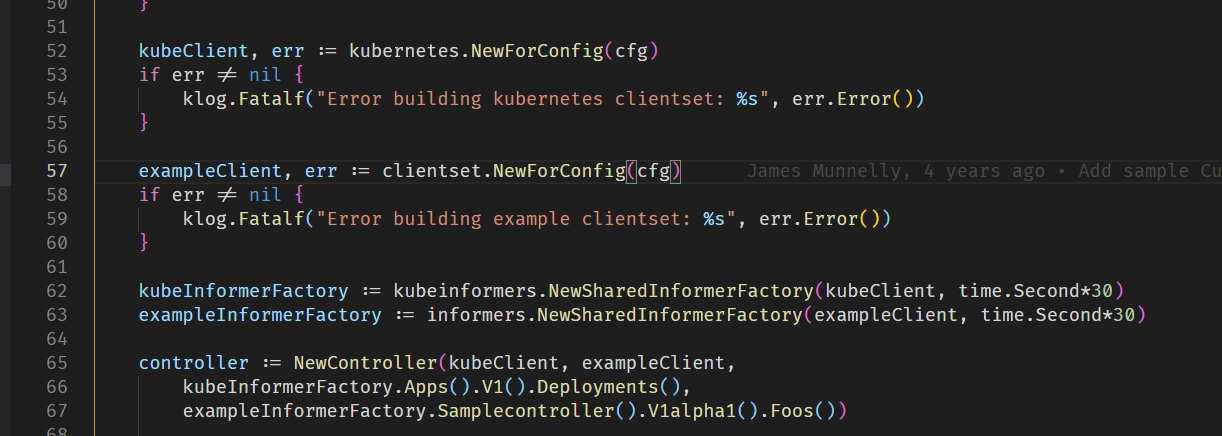
在main.go中,创建了两个client,分别对应k8s原生的clientset和foo资源的clientset
在go-client中,client主要有三种,restClient, dynamicClient, clientset,其中restClient是最底层的,可以直接通过资源名称来进行链式语法的CURD操作,常用的是Clientset,这是一个集大成者

Clientset用起来最简单,也最复杂。对几种client的介绍可以看看这篇文章https://www.kubernetes.org.cn/1309.html
创建完后,又创建了两个InformerFactory,Informer是k8s中非常重要的概念,类似于平时编写的回调函数,会监视资源的变化,而InformerFactory就是来对Informer进行控制的
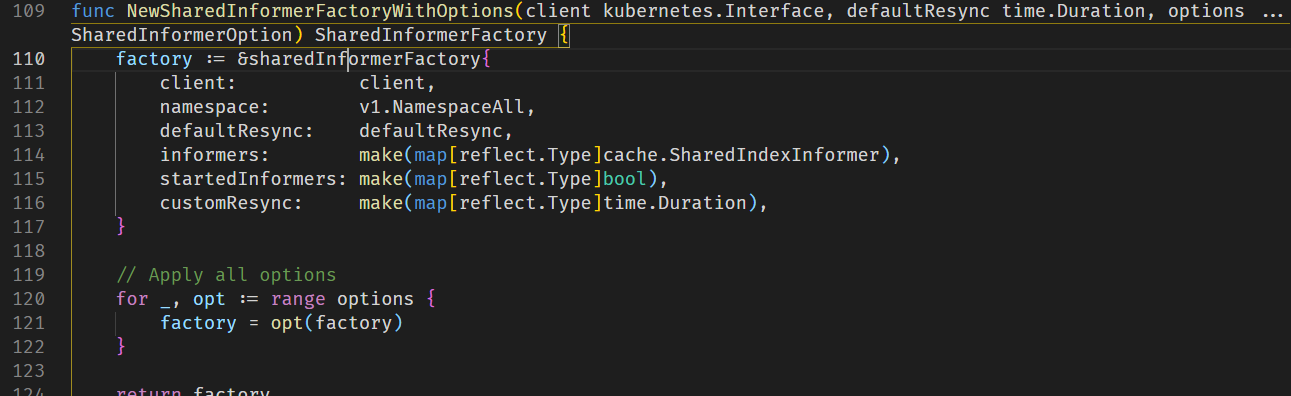
其中可以看到两个map: informers和startedInformers,来指示Informer的内容和是否启动
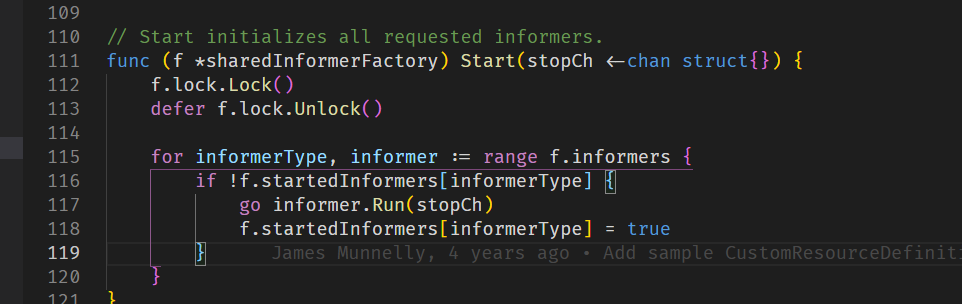
看看informerfactory的Start方法,就是通过执行Informer的Run方法让其启动
这里先看看FooInformer的定义
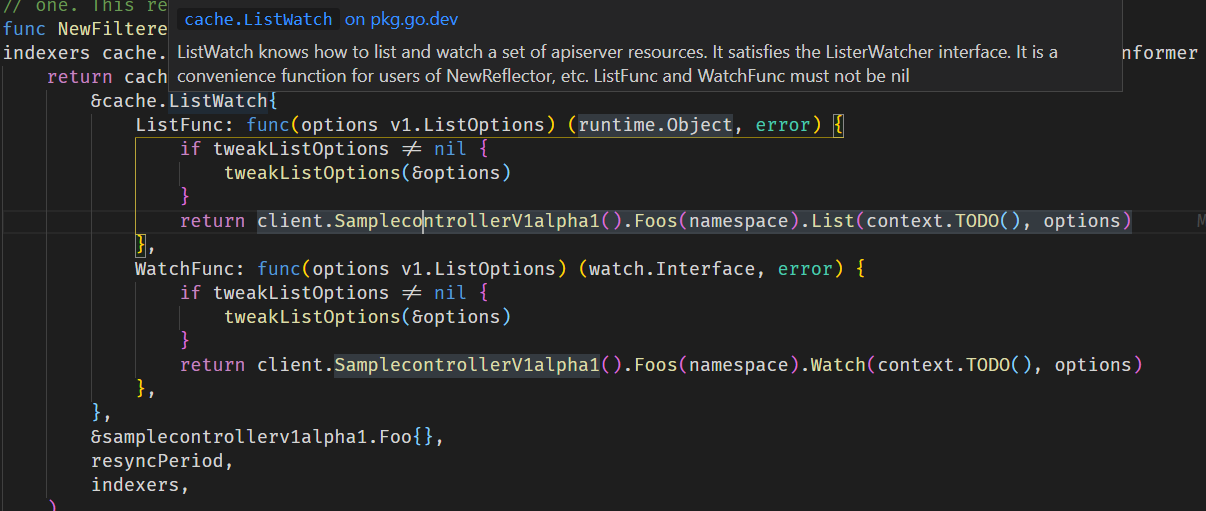
可以看到关键是传入的ListWatch结构体,结构体接受了两个回调函数,分别是通过clientset来List和Watch资源,以及Foo实例,重新同步周期和indexers。indexer就是k8s提供的一个索引器,这里查看调用就是传入了一个通过namespace索引的函数,即基于namespace索引

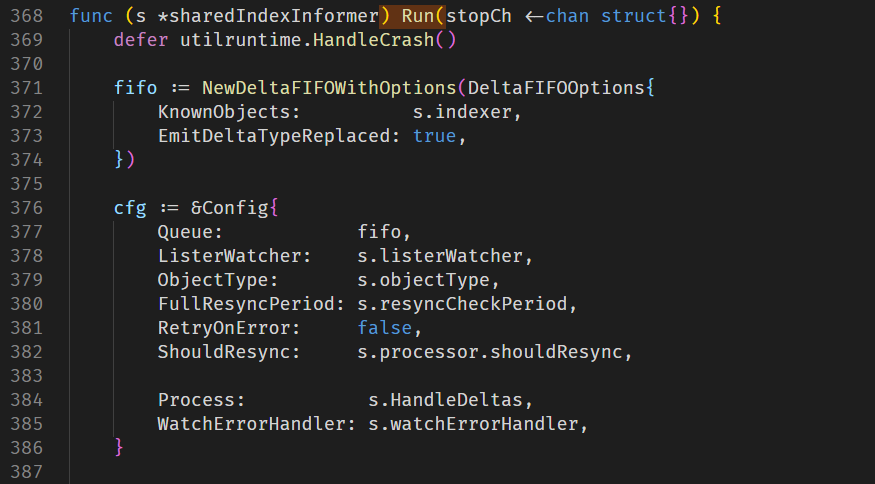
Run方法首先会创建一个FIFO队列,用于处理监听到的事件。然后创建一个Config,包括之前Informer的一些属性
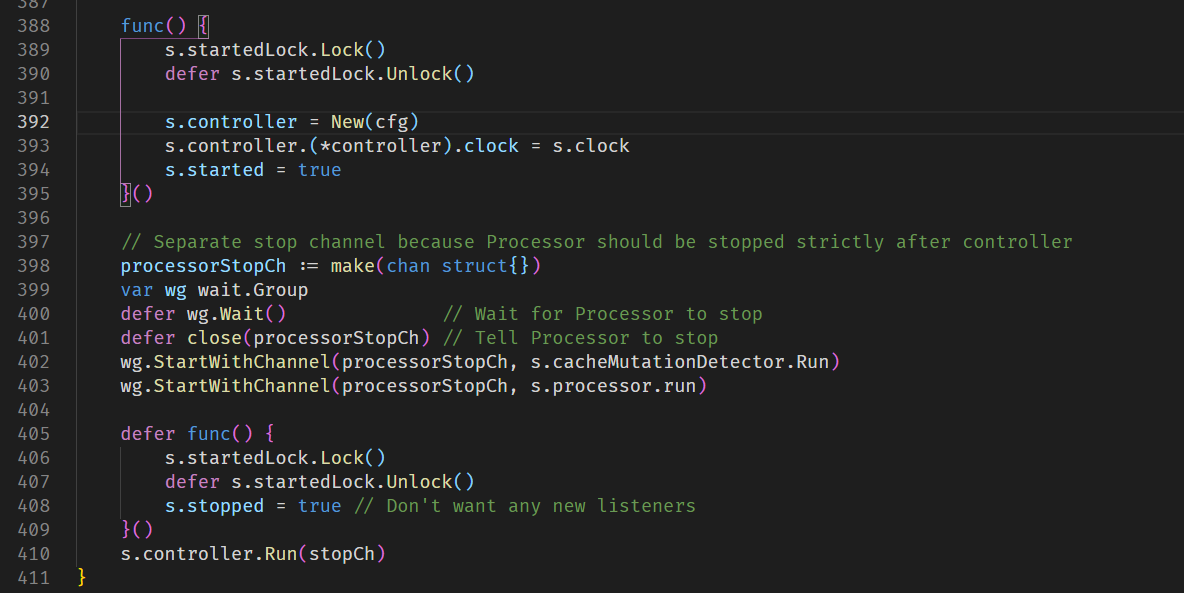
之后加锁,创建了一个controller,用于之后Informer的控制,然后让Controller运行起来,Controller的主要逻辑就是这个函数,c.config.Queue就是之前提到的FIFO队列,对于监听到的时间进行出队,并且执行对应的函数。
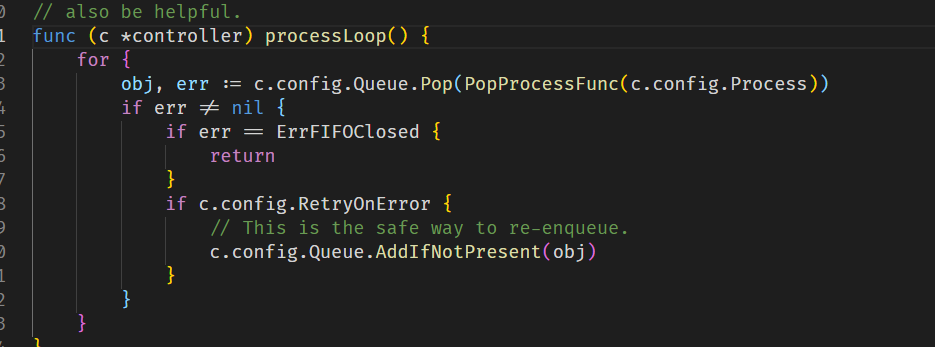
跟到这就差不多弄懂Informer了,再回到main.go看看controller做的事情
先看Controller的New函数
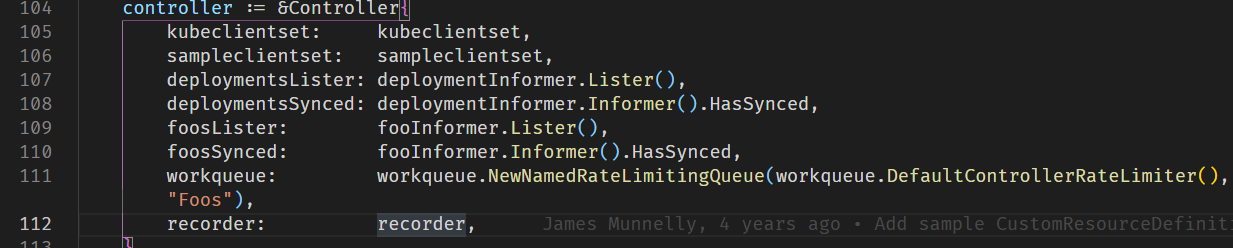
首先创建了一个包含两种资源的获取函数和是否同步的判断函数,以及一个workqueue,这个workqueue带有速度限制。
workqueue的基础定义如下
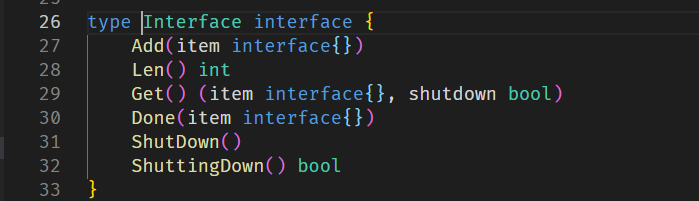
workqueue有很多类型,详细解释可以看https://blog.csdn.net/weixin_42663840/article/details/81482553,这里了解到workqueue是用来处理数据变化的就可以。
然后则是为两个informer添加了事件处理函数,这是比较关键的一步,如果我们需要自定义我们的资源监听函数也可以在这里进行。

之后则是使Controller调用Run函数,Run函数的核心就是这个函数
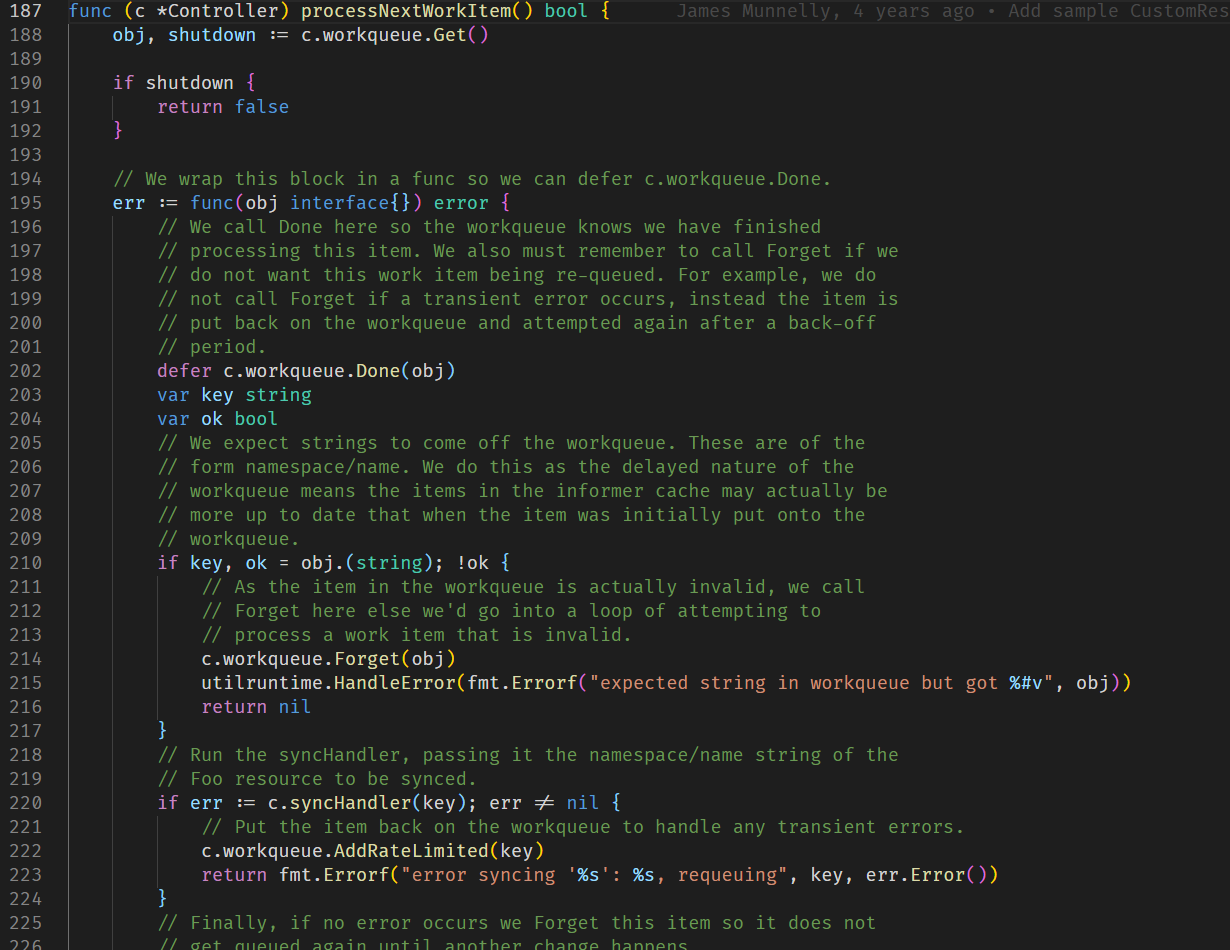
看到220行,controller对取出来的事件进行处理,如果出现错误则会再次添加到像素队列里,而syncHandler这个函数的关键逻辑就是
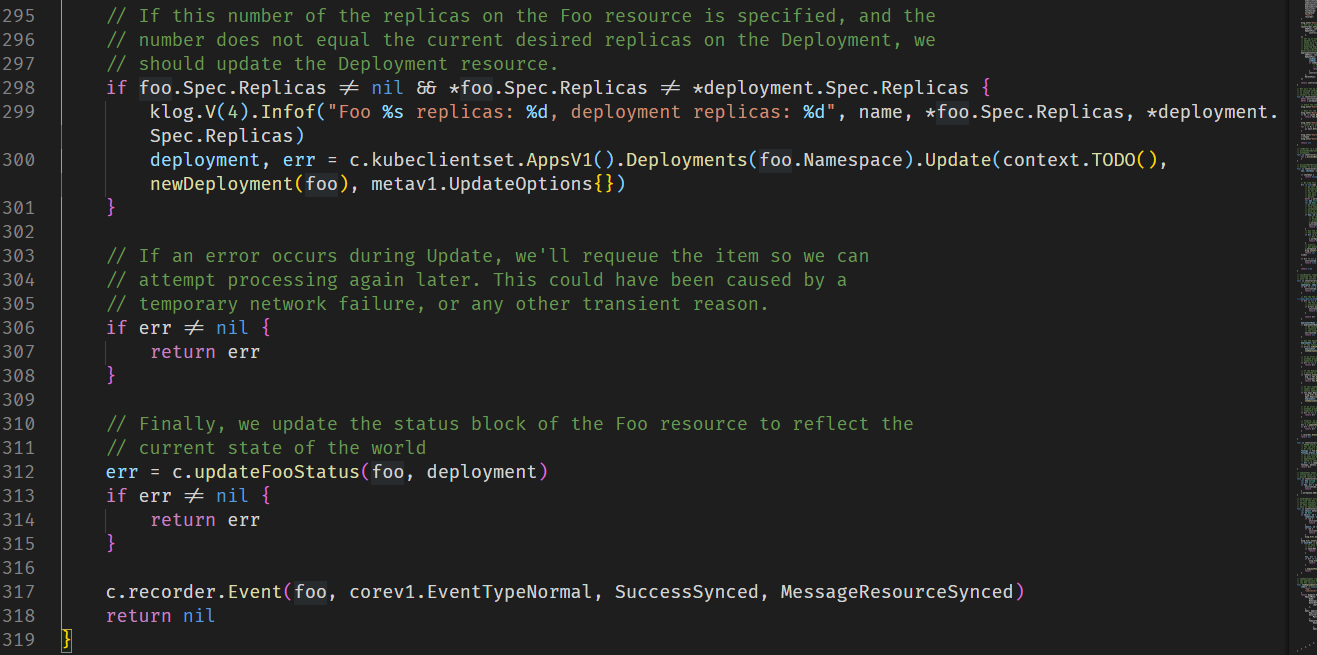
这个会将foo的当前状态和与理想状态做对比,如果不同的话会更新foo资源状态。
TiDB
TiDB集群架构
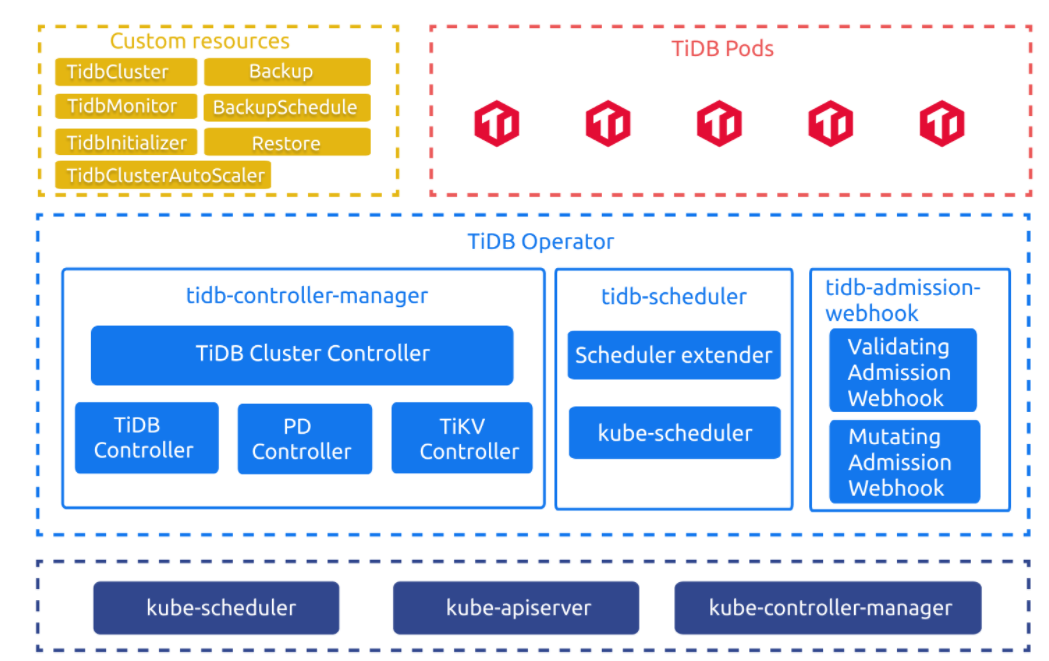
其中左上角简称CR,也是TiDB配置过程中比较重要的一部分,TidbCluster用于描述我们期望的TiDB集群,TiDB Operator主要负责将集群的调度,比如将TiDB集群逐渐配置为我们的设定(CR)状态。
TiDB所有的部署监控和运维都是由CR来执行的。
整体的控制流程如下:
- 用户通过 kubectl 创建 TidbCluster 和其他 CR 对象,比如 TidbMonitor 等;
- TiDB Operator 会 watch TidbCluster 以及其它相关对象,基于集群的实际状态不断调整 PD、TiKV、TiDB 或者 Monitor 等组件的 StatefulSet、Deployment 和 Service 等对象;
- Kubernetes 的原生控制器根据 StatefulSet、Deployment、Job 等对象创建更新或删除对应的 Pod;
- PD、TiKV、TiDB 的 Pod 声明中会指定使用 tidb-scheduler 调度器,tidb-scheduler 会在调度对应 Pod 时应用 TiDB 的特定调度逻辑。
TiDB配置
在TiDB配置基础上,主要以命令行和yaml文件为主,命令行修改的也是yaml文件,
每一个TiDB实例以—分开

主要有三个重要部分:apiVersion, kind, metadata
对于配置文件,可以通过kubectl apply -f ${file}进行部署。


